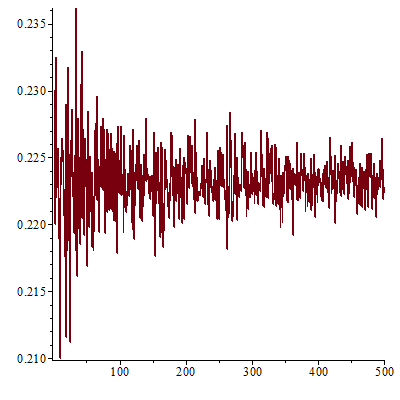
Average compression efficiency of LC with list size: 100 and trial size: 500
Natural Information Bottlenecks
Suppose we are receiving a natural number as information one decimal digit d at a time. What is the most reliable measure of the size of the incoming n in N? The number of its digits, because when d digits complete, our intuition gives a correct rough estimate for the size of n. When we see a typed decimal n, we automatically know its size, by looking at its total string length.
Therefore, a natural information bottleneck will occur when:
n ~ d*10d-1, d in {0,1,2,3,...,9}
The solutions to the above equation for d in {0,1,2,3,...,9} are:
with a,b,c,d,e,f,g,h in {0,1,2,...,9}. We proceed with some terminology:
A bottleneck digit is a digit which counts exactly this many digits following, including itself in an incoming sequence of decimal digits.
A bottleneck block is an entire block of decimal digits which starts with a bottleneck digit and includes all the digits that the bottleneck digit counts, including itself.
Note that 0 and 1 are bottleneck digits and bottleneck blocks simultaneously.
A Lossy Compression Scheme
The two definitions above of bottleneck digit and bottleneck block give rise to the following lossy compression scheme LC: Input is an arbitrary number n in N. For example:
n = 83716253849182736152435152635155243019283716263515
The compressed term LC(n) is constructed by looking at the first digit and collapsing exactly as many digits as this digit shows, including itself in the count. The process is then repeated, by starting at the digit following the collapse. We write n in a convenient format, so that the reader will see the process:
n=83716253 84918273 615243 51526 351 55243 0 1 928371626 351 5
^
^ ^
^ ^ ^ ^ ^
^ ^ ^
So:
LC(n) = 88653501935
The bottleneck digits are indicated by the arrows. The bottleneck blocks are the digit blocks between the bottleneck digits.
Let's write a program using Maple to perform this compression using lists:
> LC:=proc(L)
> local i,nL,c;
> nL:=[];
> c:=1;
> while c <= nops(L) do
> nL:=[op(nL),L[c]];
> if L[c] <> 0 then
> c:=c+L[c];
> else
> c:=c+1;
> fi;
> od;
> nL;
> end:
Example:
> L:=[8,4,1,3,2,4,5,8,6,7,5,4,3,2,5,6,7,8,9,1,0,9,4,7,5,4,2,8,7,6,9,1];
> LC(L);
[8,6,5,1,0,9,9]
Now let us measure the average performance of LC:
> RD:=rand(0..9):
> LS:=100;
> TS:=200;
> ST:=proc(n)
> local k,m,ul,cl,al,L,eff,E,s;
> E:=[];
> s:=0.0;
> for k from 1 to n do
> L:=[seq(RD(),m=1..LS)];
> ul:=nops(L);
> L:=LC(L);
> cl:=nops(L);
> E:=[op(E),evalf(cl/ul)];
> od;
> for k from 1 to nops(E) do
> s:=s+E[k];
> od;
> eff:=evalf(s/nops(E));
> end:
> EL:=[seq([n,ST(n)],n=1..TS)]:
> with(plots):
> plot(EL,style=line):
The average compression efficiency is shown by James Waldby on sci.math to be: 10/46, as follows: Let Li denote the number of times i is a leader, i.e., one of the retained digits. For any given sequence of length N, N = L0 + L1 + 2*L2 + 3*L3 + ... + 9*L9. We suppose each digit i is equally likely to be a leader, i.e., that the Li are approximately equal to some L, hence N ~ 46*L. The number of retained digits is L0 + L1 + ... + L9 ~ 10*L, so the average compression efficiency is about 10/46 ~ .2173913043.
Next we write a procedure to extract the digits of n as a list:
> #convert a number to a list of digits
> N2L:=proc(n)
> local d,L,RL,Llen,m;
> m:=n;L:=[];RL:=[];
> while m>0 do
> d:=10*frac(m/10);
> RL:=[op(RL),d];
> m:=floor(m/10);
> od;
> Llen:=nops(RL); #reverse list
> for m from 1 to nops(RL) do
> L:=[op(L),RL[Llen-m+1]];
> od;
> L;
> end:
Finally we apply the compression scheme to π and e:
> Digits:=40;
> for n from 1 to 15 do
> print(floor(10^(n-1)*evalf(Pi,n)),LC(N2L(floor(10^(n-1)*evalf(Pi,n)))));
> od;
3, [3]
31, [3]
314, [3]
3142, [3, 2]
31416, [3, 1, 6]
314159, [3, 1, 5]
3141593, [3, 1, 5]
31415927, [3, 1, 5]
314159265, [3, 1, 5]
3141592654, [3, 1, 5, 4]
31415926536, [3, 1, 5, 3]
314159265359, [3, 1, 5, 3]
3141592653590, [3, 1, 5, 3, 0]
31415926535898, [3, 1, 5, 3, 9]
314159265358979, [3, 1, 5, 3, 9]
> for n from 1 to 15 do
>
print(floor(10^(n-1)*evalf(exp(1),n)),LC(N2L(floor(10^(n-1)*evalf(exp(1),n)))));
>od;
3, [3]
27, [2]
272, [2, 2]
2718, [2, 1, 8]
27183, [2, 1, 8]
271828, [2, 1, 8]
2718282, [2, 1, 8]
27182818, [2, 1, 8]
271828183, [2, 1, 8]
2718281828, [2, 1, 8]
27182818285, [2, 1, 8]
271828182846, [2, 1, 8, 6]
2718281828459, [2, 1, 8, 5]
27182818284590, [2, 1, 8, 5]
271828182845905, [2, 1, 8, 5]
Note how both constants manage to almost re-encode themselves under the lossy compression scheme, with an error (n=20):
>evalf(abs(3.1539-Pi));
.012307346
evalf(abs(2.18525-exp(1)));
.533031828
π re-encodes itself a bit better, because the re-encoding is good to almost two decimal digits, whereas e re-encodes itself by missing the second digit. Coincidence? Now try π/e:
>for n from 1 to 15 do
>print(floor(10^(n-1)*evalf(Pi/exp(1),n)),LC(N2L(floor(10^(n-1)*evalf(Pi/exp(1),n)))));
>od;
1, [1]
11, [1, 1]
115, [1, 1, 5]
1156, [1, 1, 5]
11557, [1, 1, 5]
115573, [1, 1, 5]
1155727, [1, 1, 5]
11557274, [1, 1, 5, 4]
115572735, [1, 1, 5, 3]
1155727350, [1, 1, 5, 3]
11557273498, [1, 1, 5, 3, 8]
115572734979, [1, 1, 5, 3, 7]
1155727349791, [1, 1, 5, 3, 7]
11557273497909, [1, 1, 5, 3, 7]
115572734979092, [1, 1, 5, 3, 7]
π/e seems to re-encode itself even better than the two numbers themselves, separately:
evalf(abs(Pi/exp(1)-1.1537),8);
.0020274
Fixed Point Numbers of this Lossy Compression Scheme
Can we find other numbers n such that |0.n - 0.LC(n)| < ε for a given ε, except the trivial cases of n consisting of the same digit? Better yet, can we construct such numbers? A number like this would be a non-trivial fixed point of this compression scheme. Non-trivial fixed points are called 2d numbers (or two-dimensional numbers).
The following is a Maple procedure for generating such numbers:
>RD:=rand(0..b-1):#random in 0..b-1
>RD();
>RDE:=proc(n)local d;#random in 0..b-1 exclusive of n
>if n=-1 then d:=RD();
>else
> d:=RD();
> while d=n do
> d:=RD();
> od;
>fi;
>d;
>end:
> GFPLC:=proc(sL,blocks)
> local sM,cL,c,n,m,match,nextd;
> cL:=LC(sL);
> match:=true;
> for n from 1 to nops(cL) do
> match:=match and (cL[n]=sL[n]);
> if match=false then ERROR(`Initial digits don't match: Seed cannot generate fixed
point sequence!`);
> else nextd:=n+1;fi;od;
> sM:=sL;
> c:=1;
> #first adjust the resultant list to be exact
> while c <= nops(sM) do
> if sM[c]=0 then c:=c+1 else c:=c+sM[c];fi;
> od;
> if c > nops(sM) then
> for n from c-nops(sM)-1 to 1 by -1 do
> sM:=[op(sM),RDE(n)];
> od;
> fi;
> n:=1;
> while n <= blocks do
> sM:=[op(sM),sM[nextd]];#sL will exhaust it!!
> if sM[nextd] > 0 then
> for m from sM[nextd]-1 to 1 by -1 do
> sM:=[op(sM),RDE(m)];
> od;
> fi;
> nextd:=nextd+1;
> n:=n+1;
> od;
> sM;
> end:
Let's test it!
> L:=[3,5,1,4,2];
> GFPLC(L,1);
Error, (in GFPLC) Initial digits don't match: Seed cannot generate fixed point
sequence!
Indeed! Note that LC(n) = [3,4,...] and the second digit does not match. This digit sequence cannot therefore generate a fixed point stream. Let's try instead:
> L:=[3,5,1,5,0];
> GFPLC(L,8);
[3,5,1,5,0,0,7,6,1,5,2,6,9,9,0,0,7,1,6,2,3,3,7,6,3,6,4,1,9,1,5,8,2,7,4] (1)
> LC("); #verify compression!
[3,5,1,5,0,0,7,6,1,5]
and voila! We have gotten ourselves a finite stream of digits, which we can extend to an arbitrary length fixed point stream, by varying the parameter "blocks". Such numbers are called 2d numbers.
A 2d number broken down to its bottleneck blocks can be read in two ways, left to right and top to bottom using the bottleneck digits. This means: Read the following number from top to bottom and from left to right. Reading thus, the digits match the digits if you only read from top to bottom and only the first digit of the number in every row:
Now, let bn,k={e1, e2, e3..., ek} be a bottleneck block of size |bn,k|=k.
It's now fairly obvious that the first digit of b is related with d through the following property for all n ≥ 1:
which you can verify for yourself in the above sequence.
An Application to Error Correcting Codes
The fixed point sequences have an interesting property: They can recover themselves backwards completely, if we only have enough digits of the sequence which starts at a bottleneck digit of the original sequence provided a certain structural condition is met.
Suppose for example that we receive the above sequence (1) one digit at a time, and we have lost all digits prior to those from position 10 onwards. We also know that the digit at position 10 is a bottleneck. Let's write down what we have so far:
> L:=[5,2,6,9,9,0,0,7,1,6,2,3,3,7,6,3,6,4,1,9,1,5,8,2,7,4];
Now let's compress the above:
> LC(L);
[5,0,0,7,6,1,5]
Surprise! The digits left of 5 are the digits leading our [5,2,6,...].
So we add them to the list, up to suitable successive bottleneck digits to the left:
> L:=[5,0,0,7,6,1,5,2,6,9,9,0,0,7,1,6,2,3,3,7,6,3,6,4,1,9,1,5,8,2,7,4];
> LC(L);
[5,1,5,0,0,7,6,1,5]
Surprise again! The first two digits are the leading digits before our [5,0,0,7,...]
We add those to the list, but we have no bottleneck digit, so the next bottleneck to the left must necessarily be a 3, hence:
> L:=[3,5,1,5,0,0,7,6,1,5,2,6,9,9,0,0,7,1,6,2,3,3,7,6,3,6,4,1,9,1,5,8,2,7,4]
and we have completely recovered the entire string!
Here's a more complex example:
> L:=[9,5,1,5,0];
> G:=GFPLC(L,20);
>
G:=[9,5,1,5,0,9,8,6,2,5,2,6,9,5,1,5,2,8,1,0,0,9,0,7,8,6,5,9,7,3,8,6,1,1,6,6,8,7,6,7,8,6,1,5,2,2,5,2,7,6,0,2,7,6,
4,2,5,3,9,9,7,4,6,7,0,9,4,2,5,7,1,4,4,1,5,8,8,9,1,2,6,8,5,3,1,5,5,5,0,1,0,0];
Suppose that we have only:
>
L:=[1,5,2,8,1,0,0,9,0,7,8,6,5,9,7,3,8,6,1,1,6,6,8,7,6,7,8,6,1,5,2,2,5,2,7,6,0,2,7,6,4,2,5,3,9,9,7,4,6,7,0,9,
4,2,5,7,1,4,4,1,5,8,8,9,1,2,6,8,5,3,1,5,5,5,0,1,0,0];
> LC(L);
[1,5,0,9,8,6,2,5,2,6,9,5,|,1,5,2,8,1,0,0] (recovered digits show left of "|").
We pick the next block to the left and add it to the list:
>
L:=[5,2,6,9,5,1,5,2,8,1,0,0,9,0,7,8,6,5,9,7,3,8,6,1,1,6,6,8,7,6,7,8,6,1,5,2,2,5,2,7,6,0,2,7,6,4,2,5,3,9,9,7,4,6,7,
0,9,4,2,5,7,1,4,4,1,5,8,8,9,1,2,6,8,5,3,1,5,5,5,0,1,0,0];
> LC(L);
[5,1,5,0,9,8,6,2,|,5,2,6,9,5,1,5,2,8,1,0,0] (recovered digits show left of "|").
We can add a bottleneck digit 9 at the start, so then
>
L:=[9,5,1,5,0,9,8,6,2,5,2,6,9,5,1,5,2,8,1,0,0,9,0,7,8,6,5,9,7,3,8,6,1,1,6,6,8,7,6,7,8,6,1,5,2,2,5,2,7,6,0,2,7,6,4,2,
5,3,9,9,7,4,6,7,0,9,4,2,5,7,1,4,4,1,5,8,8,9,1,2,6,8,5,3,1,5,5,5,0,1,0,0];
Check compression:
> LC(L);
[9,5,1,5,0,9,8,6,2,5,2,6,9,5,1,5,2,8,1,0,0]
and we have recovered the entire string successfully.
To recover the beginning of the sequence, we need to have received enough bottleneck blocks such that the compression is able to recover enough leading digits close to our starting digits on our list.
The above scheme doesn't always work, however. The following examples were pointed out to the author by Tim Little of sci.math. Consider the streams:
If the stream is truncated at the bottleneck point 2754..., we get:
>L:=[2,7,5,4,7,3,1,4,5,0,9,3,9,1,2,8,1,2,1,7,8,7,7,3,3,9,5,0,5,4,2,4,0,5,6,7,7,7,6,5,3,2,3,4,2,1,4,4,1,6,5,6,7,3,5];
> LC(L);
>[2,5,4,3,2,1,|,2,7,5,4,7,3,1,4,5] (recovered digits show left of "|")
Now the above has problems. We can pick up just the digit (1), the two digits (2,1), the three digits (3,2,1), the four digits (4,3,2,1), the five digits (5,4,3,2,1) or the digits (7,2,5,4,3,2,1) and continue the algorithm to give us different predictions with an updated stream.
If we pick the bottleneck digit (7) long with the sequence (2,5,4,3,2,1), we get the first sequence above. If we pick the block (5,4,3,2,1), we get:
L:=[5,4,3,2,1,2,7,5,4,7,3,1,4,5,0,9,3,9,1,2,8,1,2,1,7,8,7,7,3,3,9,5,0,5,4,2,4,0,5,6,7,7,7,6,5,3,2,3,4,2,1,4,4,1,6,5,6,7,3,5];
> LC(L);
[5,2,|,5,4,3,2,1,2,7,5,4,7,3,1,4,5] (recovered digits show left of "|")
Add the bottleneck digit (3) and we get the second sequence above. If we pick the block (4,3,2,1), we get:
L:=[4,3,2,1,2,7,5,4,7,3,1,4,5,0,9,3,9,1,2,8,1,2,1,7,8,7,7,3,3,9,5,0,5,4,2,4,0,5,6,7,7,7,6,5,3,2,3,4,2,1,4,4,1,6,5,6,7,3,5];
> LC(L);
[4,2,5,|,4,3,2,1,2,7,5,4,7,3,1,4,5] (recovered digits show left of "|")
Add the bottleneck digit (4) and we get the third sequence above.
Such cases cannot predict a unique sequence, since there's no way to choose the next block uniquely. Even though each combination choice in principle determines a unique sequence and all choices can be enumerated, the number of all enumerations may be quite large, particularly if the receiver has lost many initial digits from the sent message. Such fixed points are called ambiguous.
Next verify that any fixed point which contains nested bottleneck blocks must necessarily be an ambiguous fixed point. A nested bottleneck block is a block of length k in which counting from right to left and from 1 to k, at least two entries in the block equal the counting index. For example, the following are nested bottleneck blocks:
Fixed points which contain no nested bottleneck blocks exist. If we modify the procedure GFPLC to generate digits which are not equal to their counting index from right to left inside their initial bottleneck blocks, we can generate them easily (the modification already exists in proc GFPLC above: Note the calls RDE(m) and RDE(n) inside its body). For example:
> L:=[3,1,4,1,4];
> G:=GFPLC(L,30);
G:=[3,1,4,1,4,0,8,5,1,4,4,9,0,0,8,9,4,6,7,6,0,8,5,0,6,1,9,1,4,9,7,0,4,0,6,0,9,0,8,7,1,7,0,8,4,0,0,8,1,8,7,5,7,0,
9,9,3,1,7,7,5,7,3,9,4,0,0,6,6,9,6,4,7,2,7,4,3,3,7,9,4,6,6,8,5,9,2,0,8,0,0,7,1,2,9,3,5,5,7,0,5,0,6,6,1,2,4,3,1,9,1,6,
5,3,9,6,4,8,1,4,4,5,2,9,7,0,0,1,1,5,3,8,7,5,7,6,5,7,9,0,4,9,0,7]
> LC(");#check compression
[3,1,4,1,4,0,8,5,1,4,4,9,0,0,8,9,4,6,7,6,0,8,5,0,6,1,9,1,4,9,7,0,4]
and G is a non-ambiguous fixed point. We now have the following:
Theorem:
A non-ambiguous fixed point of LC predicts a unique sequence.
Proof:
Choose a starting bottleneck block in order to recover more digits towards the beginning of the stream. Because the fixed point contains no nested bottlenecks, the recovery process cannot extract a stream of digits which contain nested bottlenecks, hence the recovery process is unique and hence the recovered stream is unique. QED.
The above theorem allows us to transmit information in a lossless and recoverable way, provided nested bottlenecks do not occur. A message can be encoded in the d-1 digits inside the bottleneck blocks following the bottleneck digit d > 1. The message is then transmitted. If the message is long enough and new digits keep coming in, by receiving enough bottleneck blocks we can recover the original message all the way to its beginning.
An alternate variant of the above scheme was suggested by Tim Little, using fixed length bottleneck blocks. For example, to encode the sequence:
635841021863871721799207213279185259441917332264,
one duplicates the digits of the sequence with length 5 blocks, as:
Verify that any sequence segment starting at a block boundary recovers the entire sequence backwards completely and unambiguously. For example: Having only the sequence: 31863 58717 82179 69207 42132 17918 05259 24419 31733 12264, the recovery process will generate the sequence: 358 64102|31 (predicted left of "|"), so updating the sequence to include the new 5-block, we have: 64102 31863 58717 82179 69207 42132 17918 05259 24419 31733 12264, and the new recovery process will generate the sequence: 6358|6410231 (predicted left of "|") and the whole sequence is completely recovered.
Note that in this case, the digits satisfy:
which can be verified that holds for the latter sequence message.
The above compression scheme LC can be shown to be a compression sub-scheme of the so-called RLE or Run-Length-Encoding compression scheme.
An Application to Lossless Transmission and Recovery
Using the routines in the worksheet for example, choose a text message consisting of letters of the English Alphabet (codes: 0..25), you can put the letters into a list and convert the list to its base 26 equivalent number. Then you can do a base conversion to get a base 10 equivalent number, whose digits you can put in a new list which will contain only digits 0..9. Then transmit the latter list. Assuming you get only a "correct" part of a later segment of the message, you can recover the prior message as above. Finally convert the list back to base 26 to get the entire message stream.
Download the complete theory behind all the above along with some Maple code for this scheme, here.